How ConvertKit deploys multiple times a day across 15 time zones


ConvertKit is a fully remote team with developers scattered from California to South East Asia. We use this as an advantage to continually build and release new code to production. We deploy anywhere from two to ten times a day over 18 hours. We’ve done this by combining our most vital tools to create a CI/CD pipeline from Slack, Github, CircleCI, AWS… and Bob Ross.
The importance of a healthy CI/CD pipeline
Getting code into production is one of the most important and difficult problems a software company has to solve. Getting it there quickly and safely is even more important. Continuous integration, continuous deployment, and DevOps are popular terms that have become something of a meme in recent years. Despite the potential misuse of the words, it cannot be overstated how important a good CI/CD pipeline is to a product-focused high-growth SaaS company.
It is such an important problem to solve that extensive research is done on it and has produced books such as Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations and the State of DevOps Report. They both cover engineering organizations of all sizes and compare their performance as businesses based on their software delivery performance. The overwhelming consensus is that a major difference between high-functioning vs a low performing organization lies in their ability to deliver software quickly and accurately.
The more often a company is able to deliver software, the more often they are increasing business value. Companies that deploy multiple times per day in a fast, automated way, are capable of delivering consistent value and are able to iterate faster than companies with inconsistent or fixed release cycles.
There is an additional benefit of a fast deployment pipeline is that the mean time to recovery (or MTTR) from a production problem is typically much faster than low performers. Within ConvertKit, the fact that we can deploy or rollback quickly means that our MTTR is a matter of seconds.
DevOps is not a job or a title. It’s a methodology adopted by an entire organization to increase software delivery frequency and accuracy. ConvertKit follows DevOps principals by having a version controlled, automated, deployment pipeline that is used by everyone from developers, QA, and product alike. We achieve this with the help of a Slack bot named after Bob Ross.
Background
I believe the more often you do a scary thing, the less scary it becomes. This is particularly helpful for things like production deployments. As long as the ease of deployment is high and the speed of our tests and builds are fast, then we are capable of deploying frequently and safely. Since our deployments are automated, we also can either push a hotfix or roll back quickly in the rare event of a bad release.
The process of getting code into production at ConvertKit is as follows:
- Submit a PR
- Pass tests and code review
- Merge PR
- Wait for the master test suite to pass
- Deploy to production using the Slack slash command
/stop deploy convertkit - ???
- Profit
The first four steps of that flow are pretty universal at most software companies. However, I’ll be going over step five and how it works behind the scenes.
StoP Bob
Bob Ross was a childhood hero of mine and the author of the quote, “We don’t make mistakes, just happy little accidents.” It’s this attitude that we apply to our deployment pipeline and the reason why we created a Bob Ross bot to manage and automate all of our deployments. It’s also the reason why I’m going to prove the following tweet wrong by showing you The Joys of Deploying with Bob Ross.
"We don't make mistakes, just happy little accidents"
— I Am Devloper (@iamdevloper) September 30, 2019
Bob Ross would be terrible at DevOps.
StoP Bob stands for Slack-to-Production Bob Ross. When an engineer enters /stop deploy convertkit into Slack, a modal will pop up. This modal has two inputs:
- the SHA of the git commit needing to be released and
- the environment to release.
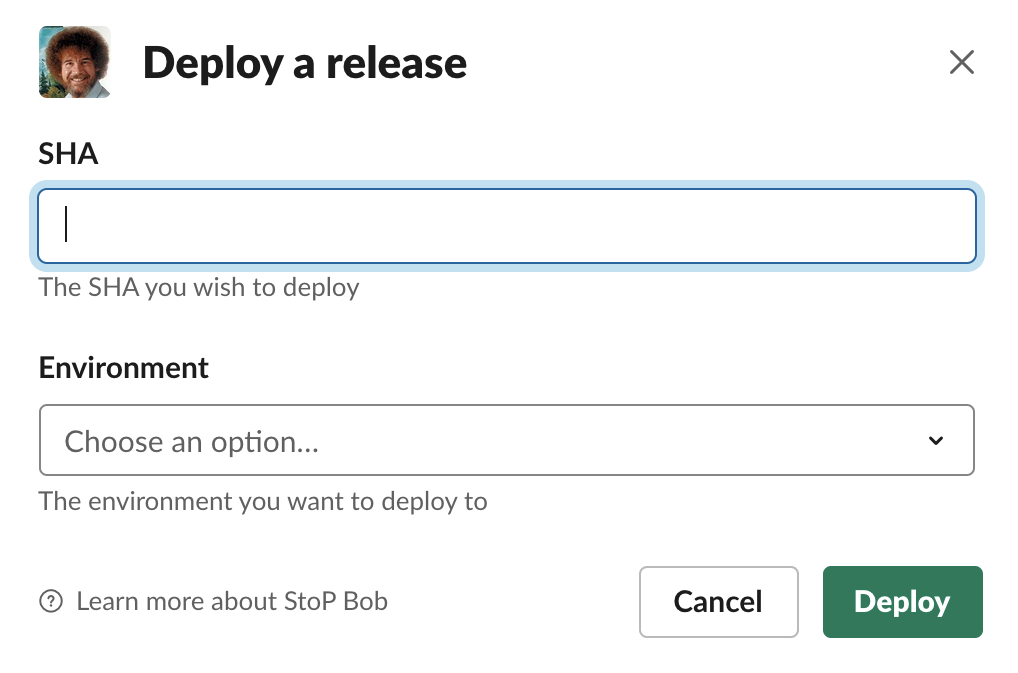
Once the engineer submits the modal, Bob will post to the channel that the deployment has started and will create a Slack thread for updates.
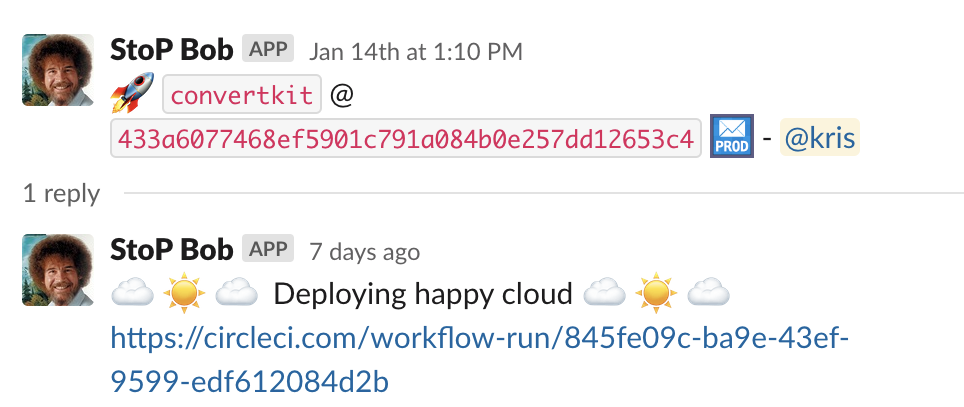
Bob will also post in our dedicated changelog channel about the changes being deployed in the newest release.

What’s happening behind the scenes is the Bob server creates a git tag and Github release based on the git SHA that was submitted in the modal. That tag is picked up by CircleCI that runs a deployment workflow that I’ll go over next.
Github and CircleCI
CircleCI has a native Github integration. This is convenient because it gives us an easy way to connect the two. We run CircleCI workflows for all of our deployments, and the jobs are filtered based on git tags. Those workflow job filters look something like this.
version: 2
workflows:
version: 2
deploy_production:
jobs:
- "Post Changelog":
filters:
branches:
ignore: /.*/
tags:
only:
- /^production-.*/
- "Deploy Master":
filters:
branches:
ignore: /.*/
tags:
only:
- /^production-.*/The above job definitions correlate to a CircleCI workflow that looks like this.
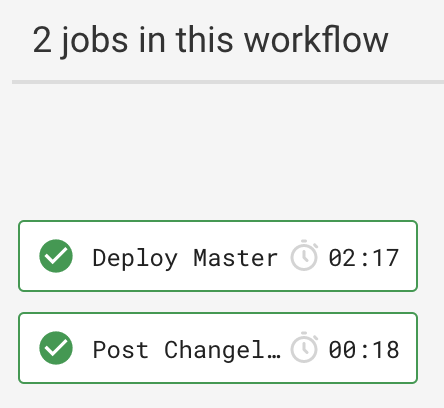
Those two jobs are responsible for posting the changelog to the changelog channel and deploying the master branch to production using AWS CodeDeploy.
AWS
We currently use AWS CodeDeploy to handle all of our deployments, and we’ve only been using docker in production since October 2019. We’re currently in the process of migrating to Kubernetes, but for now, we still use CodeDeploy.
CircleCI assumes an AWS role that has the necessary permissions to trigger a CodeDeploy deployment. These roll out with zero downtime by taking at-most half of our servers out of rotation, installing the latest release, and then progressing to the next half. Every server has to pass health checks, and if the health checks fail, then the deployment fails and doesn’t continue. This is another absolute necessity that gives all of the engineering department peace of mind.
As the new release rolls out, we get an alert on Slack, notifying us that the release was successful, and the latest version is in rotation.
We rinse and repeat the above steps up to eight times a day for a steady stream of successful releases and improvements for our customers.

Conclusion
Bob is really good at deploying our app. When a deployment is triggered, it only takes a few minutes before it ends up on our production servers. It’s a repeatable process that makes deploying an easy thing to do with enough safeguards to decrease the stress engineers feel around deploying.
The Joys of Deploying with Bob Ross all come from having an automated release pattern that enables any engineer to push code into production when they’re ready. Taking inspiration from Bob Ross himself, I believe every day is a good day when you deploy and Bob Ross is helping the ConvertKit team build a happy little cloud that we’re all proud of.